Autores:
Diego Alejandro Moreno Gallón, Germán Holguín Londoño, Mauricio Holguín Londoño
Problema
En Colombia entre el año 2020 y el 2022, por pérdidas no técnicas se han perdido alrededor de USD$401M en el sistema de distribución de energía eléctrica, y año a año van aumentando. Se requiere explorar nuevas tecnologías para identificar instalaciones fraudulentas, y recuperar la energía que fue utilizada pero no facturada.
Típicamente en el sector eléctrico, se realiza la detección de pérdidas no técnicas de manera manual, y requiere meses para poder identificar los focos de pérdidas, por lo que se necesitan avances en infraestructura, analítica de datos, big data e inteligencia artificial para mejorar la frecuencia y el indice de detección de pérdidas no técnicas.
Para este problema se plantea usar la infraestructura de medición avanzada (AMI) , ubicada como macromedidor donde se registra el total de energía suministrada a un conjunto de uduarios, ver figura, 1.
Se desea determinar si es posible clasificar una instalación como fraude, solamente con la información provista por las variables eléctricas de los macromedidores AMI, utilizando métodos de aprendizaje de máquina y teniendo en cuenta que debe ser una metodología escalable.
Base de datos
Se realizó la limpieza y unión de la base de datos entregada por un operador de red (OR) eléctrico en Colombia; la cual contiene 4 tablas, un total de 88 variables, 23.5 millones de registros, y como resultado se crea una tabla con 10 variables y 3.7 millones de registros con una frecuencia de muestreo de horas. Al tener la base de datos, el siguiente paso es obtener las clases ya que esta base no las contiene. Dentro del proceso del OR se tiene que la cuadrilla de revisión, va a la instalación y dictamina si es positivo para fraude, al ser marcada como tal se puede marcar en una columna adicional dicha etiqueta.
Se tiene que el 0.4% de los registros, terminan siendo marcados como fraudes y que solo dicha etiqueta goza de verificación. Pero aquellos registros sin dicha etiqueta no han tenido ninguna verificación, por lo tanto, la base de datos tendría dos clases: FRAUDES y OTROS. Al verificar un poco más a fondo el como surge la etiqueta de FRAUDE se tiene que se despachó una cuadrilla de verificación a ese macromedidor en particular. El despacho de la cuadrilla se realiza sólo a aquellos registros que son marcados como ANORMALES. Por ende, no se debería involucrar a aquellos registros con un comportamiento NORMAL.
Etiquetado
La tarea de clasificación puede dividirse en dos etapas como puede observarse en la figura 2, siendo la primera en donde se decide ANORMAL y NORMAL para luego, solo con los casos ANORMAL determinar si son FRAUDE o OTRO. Con la estructura resultante se permite eliminar el 60% de los datos de la base de datos. Es decir que se va a tener dos etapas con modelos de aprendizaje supervisado.
Se tienen las etiquetas de otros y de fraude, falta determinar las etiquetas de la primera etapa. Para obtener las etiquetas de la primera etapa se realiza un análisis de valores extremos y detectar los valores atípicos. Esa detección de valores a típicos se realiza en información de los registros de consumo mensuales en dos puntos de medida (entre en macromedidor y el medidor del usuario), para luego llevar las etiquetas a los datos del macromedidor.
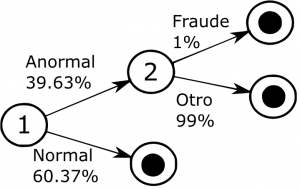
Figura 2: Árbol Jerárquico de Clasificación
Estructura Propuesta
Al tener una base de datos etiquetada, es natural, utilizar aprendizaje de máquina supervisado para entrenar los modelos que sean capaces de separar clases. Para el caso particular se utilizó uno de los métodos clásicos más robustos como lo es la maquina de soporte de vectores. Pero como este problema es de Big Data Analytics la metodología de entrenamiento, y validación deben ser escalables. La metodología se apoya en el bootstraping, en el que se selecciona un bloque aleatorio de tamaño T para entrenar un modelo, actualizar las métricas de desempeño y repetir el proceso hasta que un bloque cualquiera de tamaño T ya no modifique considerablemente las métricas, esto se puede observar en la figura 4.
Por la estructura de la metodología, va a ser necesario una infraestructura de computo especial, y es por eso que se utilizó:
- Hardware
- Computación en la Nube (Cloud Computing)
- I 32 Núcleos (64 CPUs) AMD EPYC
- I 128 GB RAM
- I 500 horas de computo
- I 50 GiB de transferencia
- I USD$1100 aprox. en Amazon AWS
- Software
- Computación Paralela Multi-proceso
- Linux Ubuntu
- Control de despacho utilizando bash scripting
- I Código fuente en Python
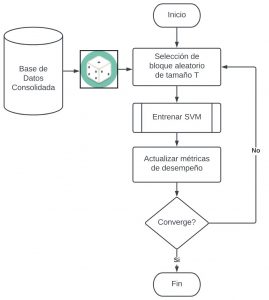
Figura 3: Árbol Jerárquico de Clasificación
A la hora de realizar el despacho se tiene que hay un problema de bin packing por lo que se requiere entregar las tareas de manera equivalente entre las unidades de procesamiento. Para solucionar el problema de despacho se utiliza una estrategia avara, y específicamente una técnica off-line First-FitDecreasing. Luego se definen las métricas de desempeño, las cuales son sensibilidad, especificidad, exactitud y precisión.
Resultados
Se diseñó e implementó una metodología para el análisis de información que proviene equipos macromedidores AMI de un OR, al utilizar aprendizaje de máquina supervisado clásico, que es capaz de realizar la clasificación de FRAUDE con un 68 % de exactitud, y más del 98 % de sensibilidad.
A partir de un experimento de Monte Carlo se demuestra que el método de entrenamiento y validación, para este problema, es escalable y que converge al utilizar muestras aleatorias de la base de datos.
Las cuadrillas típicamente se despachan a las instalaciones ANORMALES para poder identificar si hay un FRAUDE u OTRO. El índice de efectividad fraude es muy bajo, y con el sistema propuesto, aumentaría significativamente el porcentaje de detección, que según los resultados, estaría alrededor del 60 % (teniendo en cuenta la estructura jerárquica).
Referencias
[1] EMPRESAS PÚBLICAS DE MEDELLÍN. Normas Técnicas: Instalación de Macromedión. Medellín, EPM, 2017.
Bibtex
@article{gallondiego2022,
title={An{\'a}lisis de los registros de un operador de red el{\'e}ctrica nacional para la b{\'u}squeda de p{\'e}rdidas no t{\'e}cnicas},
author={Gall{\'o}n, Diego Alejandro Moreno},
year={2022},
school={Universidad Tecnol{\'o}gica de Pereira}
}