Autores:
Kevin David Ortega Quiñones, Byron S. Hernández, Jorge I. Sepúlveda, Henry Medeiros, Germán Andrés Holguín Londoño.
Problema
En la industria, se presenta un desafío crítico relacionado con la estimación de la pose (posición y orientación) del efector final de un brazo robótico articulado de 6 grados de libertad. Tradicionalmente, esta estimación se ha llevado a cabo utilizando encoders ubicados en las articulaciones del robot. Sin embargo, esta aproximación convencional se enfrenta a un problema significativo, ya que los encoders pueden acumular errores a lo largo del tiempo debido a diversas fuentes, como la fricción, el juego mecánico y las tolerancias de fabricación.
Como respuesta a esta problemática en la industria, se propone una alternativa de bajo costo y altamente efectiva: la implementación de un sistema de estimación visual basado en cámaras RGBD. Estas cámaras, que proporcionan información de color y profundidad en tiempo real, ofrecen un enfoque innovador para resolver este desafío. A través de la captura de datos visuales del entorno y el seguimiento preciso del brazo robótico en acción, se busca determinar con exactitud la posición tridimensional y la orientación del efector final.
Base de datos
Para entrenar el sistema, se creó una base de datos simulada utilizando ROS, Gazebo y un modelo de un brazo UR5. Se situaron 3 cámaras RGBD en posiciones fijas apuntando hacia el brazo. Mediante muestreo de Montecarlo se generaron poses aleatorias del brazo dentro de su espacio de trabajo. Para cada pose generada, se guardaron las imágenes RGB y de profundidad de las 3 cámaras.



Figura 2: imágenes RGB de las cámaras.



Figura 3: imágenes de profundidad de las cámaras.
Etiquetado
Además de la captura de datos visuales con las cámaras RGBD, se realizó un proceso adicional de etiquetado minucioso que añade un nivel de detalle crucial a la información obtenida. Este proceso implicó la asignación de coordenadas tridimensionales (3D) a cada una de las 6 articulaciones del brazo robótico, generando un conjunto completo de 18 etiquetas. Para proporcionar una visión más clara de este procedimiento, es importante destacar que estas etiquetas constan de tres valores que representan la posición en tres ejes diferentes: [x, y, z] para cada una de las articulaciones.
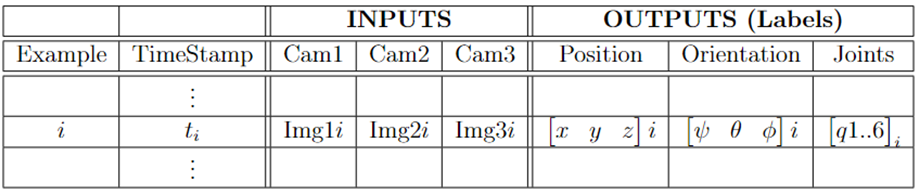
Tabla 1: estructura de datos etiquetados.
Estructura Propuesta
El modelo propuesto consiste en una red neuronal convolucional (CNN) para procesar las imágenes de las 3 cámaras RGBD. Como columna vertebral de la CNN se utiliza la arquitectura ResNet50 para extraer un vector de características de alta dimensión a partir de las imágenes de entrada.
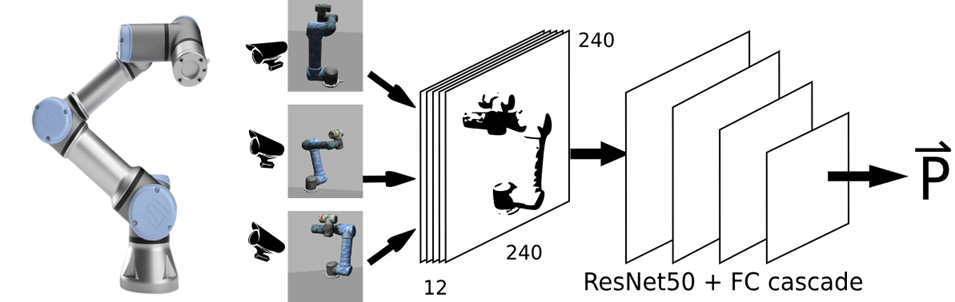
Figura 4: sistema propuesto para la estimación de la pose del efector final.
Luego, este vector de características se pasa a través de una cascada de redes neuronales totalmente conectadas, donde cada red predice las coordenadas 3D [x, y, z] de una de las articulaciones del brazo robótico. En total se tienen 6 redes neuronales totalmente conectadas en cascada, una para cada articulación.
Se compararon 3 variantes de este enfoque:
Línea base: Cada red neuronal totalmente conectada recibe únicamente el vector de características extraído por ResNet50. No hay paso de información entre las redes.
Cascada: Cada red neuronal no solo recibe el vector de ResNet50, sino también las salidas (coordenadas 3D) de la red inmediatamente anterior.
Cascada completa: Cada red recibe el vector de ResNet50 y las salidas de todas las redes anteriores en la cascada.
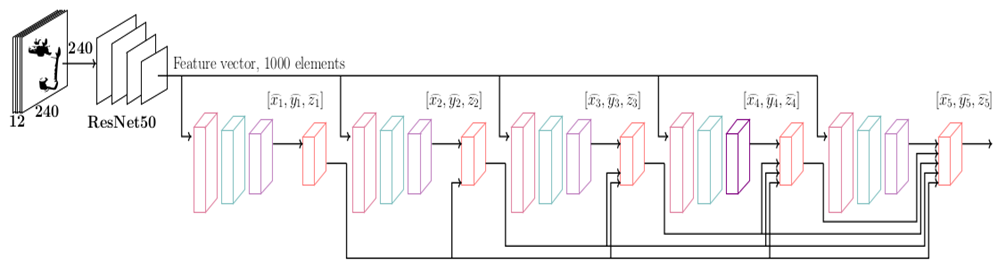
Figura 5: CNN seguida de una estructura en cascada totalmente conectada.
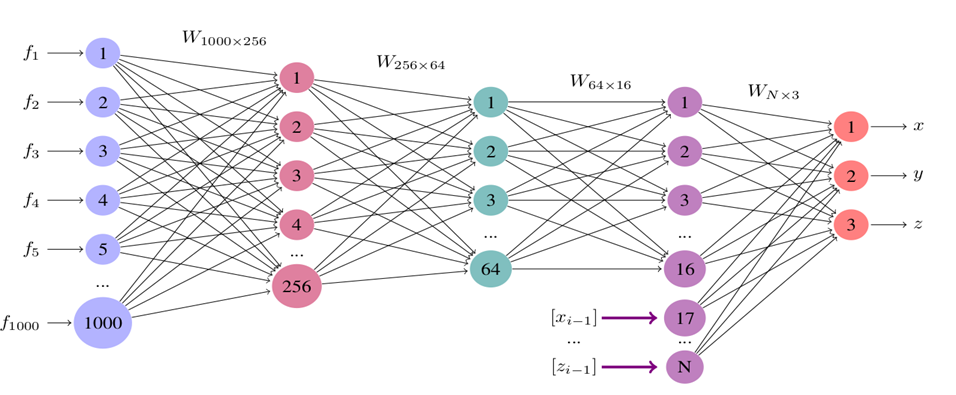
Figura 6: bloque totalmente conectado. Red Neuronal 1000-256-64-3.
La hipótesis muestra que proporcionar a cada red las estimaciones previas de las articulaciones mejoraría el rendimiento al agregar información adicional relevante para cada predicción. El método de cascada completa mostró el mejor desempeño durante la validación.
Resultados
El método de cascada completa, donde cada etapa recibe información de todas las etapas previas, obtuvo el menor error de validación. Esto indica que proporcionar las estimaciones previas mejora el rendimiento del modelo. Visualmente también se observó una buena precisión de las predicciones en 3D.
Bibtex
@article{ortegaKevin2023,
title={Seguimiento visual de un manipulador serial utilizando redes neuronales profundas},
author={Ortega, Kevin David},
year={2023},
school={Universidad Tecnol{\'o}gica de Pereira}
}